Web Audio API使用户可以在音频上下文(AudioContext)中进行音频操作,具有模块化路由的特点。在音频节点上操作进行基础的音频, 它们连接在一起构成音频路由图。即使在单个上下文中也支持多源,尽管这些音频源具有多种不同类型通道布局。这种模块化设计提供了灵活创建动态效果的复合音频的方法。
音频节点通过它们的输入输出相互连接,形成一个链或者一个简单的网。一般来说,这个链或网起始于一个或多个音频源。音频源可以提供一个片段一个片段的音频采样数据(以数组的方式),一般,一秒钟的音频数据可以被切分成几万个这样的片段。这些片段可以是经过一些数学运算等到 (比如OscillatorNode),也可以是音频或视频的文件读出来的(比如AudioBufferSourceNode和MediaElementAudioSourceNode),又或者是音频流(MediaStreamAudioSourceNode)。其实,音频文件本身就是声音的采样数据,这些采样数据可以来自麦克风,也可以来自电子乐器,然后混合成一个单一的复杂的波形。
这些节点的输出可以连接到其它节点的输入上,然后新节点可以对接收到的采样数据再进行其它的处理,再形成一个结果流。一个最常见的操作是通过把输入的采样数据放大来达到一个扩音器的作用(缩小就是一个弱音器)(参见GainNode)。声音处理完成之后,可以连接到一个目地地(AudioContext.destination),这个目地地负责把声音数据传输给扬声器或者耳机。注意,只有当用户期望听到声音时,才需要进行最后一个这个连接。
一个简单而典型的web audio流程如下:
- 创建音频上下文
- 在音频上下文里创建源 — 例如
<audio>, 振荡器, 流 - 创建效果节点,例如混响、双二阶滤波器、平移、压缩
- 为音频选择一个目地,例如你的系统扬声器
- 连接源到效果器,对目的地进行效果输出

使用这个API,时间可以被非常精确地控制,几乎没有延迟,这样开发人员可以准确地响应事件,并且可以针对采样数据进行编程,甚至是较高的采样率。这样,鼓点和节拍是准确无误的。
Web Audio API 也使我们能够控制音频的空间化。在基于源 - 侦听器模型的系统中,它允许控制平移模型和处理距离引起的衰减或移动源(移动侦听)引起的多普勒效应。
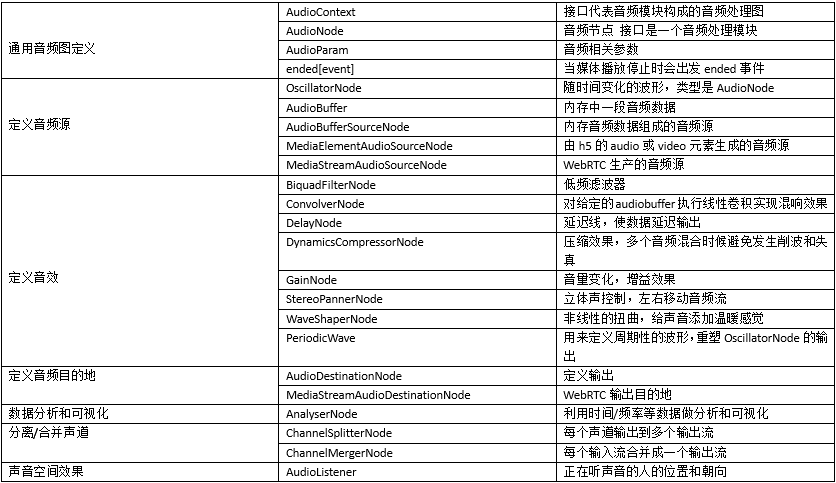
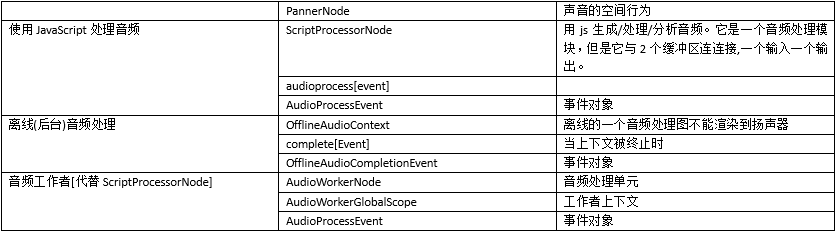
Web Audio API 接口